Blog

In the previous article, we argued that high-quality RAG systems are decided long before the first question is asked. This article explains why that is true, by unpacking one of the most misunderstood parts of RAG: ingestion.
Ingestion is often described as a preprocessing step - and that description understates what is really happening. In reality, it is the foundation on which everything else rests.
What ingestion really is (and what it is not)
At a basic level, ingestion takes documents and turns them into something a retrieval system can search.
But that description hides the real complexity.
Ingestion answers questions such as:
What is a “unit of meaning” in this document?
Which pieces of content must stay together to preserve intent?
How will this document compete with others during retrieval?
How much context should each retrieved result consume?
If those questions are answered poorly, no model - no matter how advanced - can reliably compensate.
Why “Chunking” is not just splitting text
Chunking is often reduced to a single parameter: a token size.
In practice, chunking is a structural decision.
Consider the difference between:
A narrative guide
A piece of legislation
A schedule-heavy regulation
A technical standard with deep clause nesting
Treating all of these the same way almost always leads to suboptimal outcomes.
Good chunking must respect:
Document taxonomy and structure - H1 / H2 / H3 style structures
Semantic boundaries - clauses, tables, appendices
Context preservation - what must remain together
Retrieval constraints - top-k limits, token budgets
This is why we don’t start by asking “What chunk size should we use?”. We ask “What structure is this document actually expressing?”
Understanding document structure before embedding it
Before a document is ever embedded, we analyse:
Heading depth and branching patterns
Average and maximum section sizes
Table density and numeric density
Indicators of legislative or procedural structure
Presence of schedules, appendices, and implicit sections
This allows us to infer how the document wants to be segmented - rather than imposing a generic strategy.
In many cases, the optimal strategy differs within the same corpus.
That’s why we optimise per document, not per system.
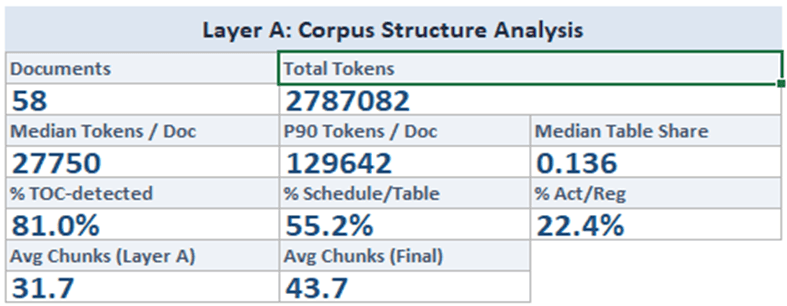
Layer A - Structural analysis before ingestion.
Documents are analysed for hierarchy depth, section sizes, table density, and structural signals before any chunking decisions are made. This establishes how each document wants to be segmented, rather than imposing a uniform strategy.
The hidden problem: Competition between documents
One of the least discussed challenges in RAG is retrieval competition.
In any real knowledge base:
Some documents are larger
Some are more structurally dense
Some naturally generate more chunks than others
Without care, these documents dominate retrieval simply because they produce more andidate chunks not because they are more relevant.
The result:
Smaller or simpler documents become effectively invisible
Retrieval diversity collapses
Users repeatedly see answers grounded in the same sources
This is not a model failure. It is an ingestion design failure.
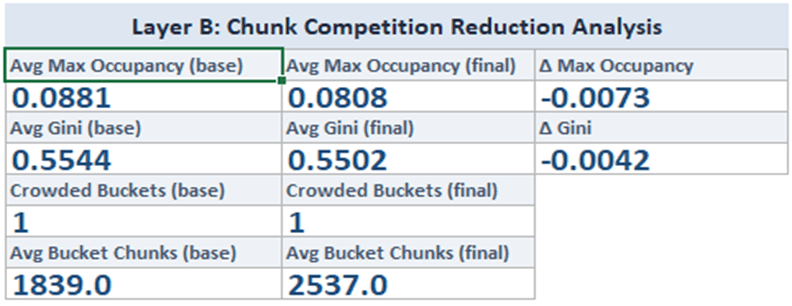
Layer B - Simulated retrieval competition across the corpus.
Chunking strategies are evaluated under fixed top-K constraints to understand how documents compete for retrieval slots. This surfaces dominance, crowd-out risk, and retrieval imbalance before documents are embedded.
Why we simulate instead of guessing
At SnapInsight, we don’t assume ingestion choices are correct.
We test them before ingestion - deliberately and systematically.
Our ingestion simulation framework explores questions such as:
How many chunks does each document produce under different strategies?
Which documents dominate top-k retrieval slots?
How evenly are retrieval opportunities distributed?
How much context is consumed per answer?
What trade-offs emerge between precision, coverage, and efficiency?
This simulation does not require live users or LLM calls.
It operates entirely on structure, metadata, and controlled retrieval assumptions.
That makes it:
Deterministic
Repeatable
Safe to run before production ingestion and safe to revisit as systems evolve
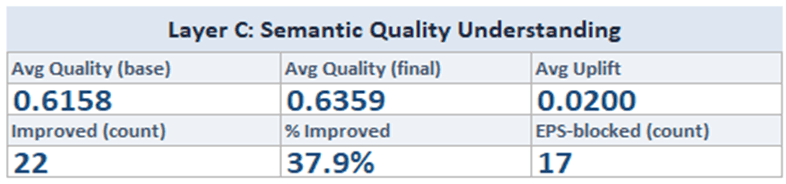
Layer C - Empirical quality validation of chunking strategies.
Candidate chunking configurations are tested using simulated retrieval and semantic matching to validate relevance and faithfulness trade-offs. Strategies are only accepted when they demonstrate measurable improvement under realistic retrieval conditions.
Optimisation is about trade-offs, not perfection
There is no single “best” chunking strategy.
Every choice balances:
Chunk coherence vs. retrieval precision
Token efficiency vs. answer completeness
Fairness vs. dominance
Structural fidelity vs. practical constraints
Our simulations are designed to surface these trade-offs explicitly, so they can be tuned - not hidden.
This is also why our systems evolve over time:
As corpora grow
As use cases change
As retrieval expectations mature
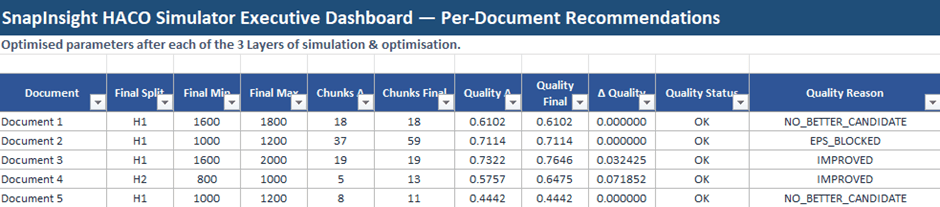
Per-document optimisation outcomes.
Each document progresses from an initial structural strategy through competition-aware refinement and, where beneficial, semantic validation. Some documents improve; others remain unchanged - reflecting deliberate trade-offs rather than forced optimisation.
Together, these stages form a closed-loop ingestion process that surfaces structural intent, competitive risk, and quality trade-offs before a single embedding is created.
Why This Work Is Often Skipped, and Why That’s Risky
Ingestion work is:
Invisible to end users
Hard to demonstrate in a demo
Slow compared to “just uploading files”
That’s why many RAG systems skip it.
But skipping ingestion design is like skipping data modelling in a transactional system - things may work initially, but failures compound over time.
When trust matters, shortcuts are expensive.
Ingestion as a first-class capability
For us, ingestion is not just a pipeline stage. It is a discipline.
It combines:
Information architecture
Retrieval theory
Systems engineering
Empirical simulation
And it exists for one reason: to give every downstream component - retrieval, ranking, generation - the best possible conditions to succeed.
Where this is going next
Ingestion is only the beginning.
The same simulation-first philosophy extends naturally into:
Faithfulness evaluation
Relevance sensitivity testing
Structural robustness under ambiguous queries
Long-term retrieval drift analysis
These are not features. They are safeguards.
The difference good chunking strategy makes
Anyone can build a RAG demo. Building a RAG system that people trust, rely on, and keep using - especially in complex domains - requires deeper work.
This is the work SnapInsight chooses to do. Not because it’s fashionable. But because quality systems are built precisely where others stop looking.
If you are interested in this topic, our article why embedding is where most RAG systems go wrong might be a great read too!
Latest































